TL;DR
Deep Residual Network (ResNet) [1]는 점차 깊어지는 (Deep) 딥러닝 아키텍처를 효과적으로 학습 가능하도록 하였으며, Residual Connection이라는 직관적이며 실제 성능 향상에 도움이 되는 구조를 제시한 딥러닝 분야의 ground breaking 한 논문입니다. 이 글에서는
https://towardsdatascience.com/an-overview-of-resnet-and-its-variants-5281e2f56035
An Overview of ResNet and its Variants
After the celebrated victory of AlexNet [1] at the LSVRC2012 classification contest, deep Residual Network [2] was arguably the most…
towardsdatascience.com
해당 링크를 참고하여, ResNet의 두 가지 후속 연구방향: (i) ResNet 구조를 결정하기 위한 후속 연구와 (ii) Improved ResNet (DenseNet, ResNeXt)를 소개하고, 저 역시 팔로업하고자 합니다.
Revisiting ResNet
Universal approximation theorem에 따르면 하나의 레이어를 가진 Neural Network가 임의의 function도 근사할 수 있는 능력을 가졌음을 보였습니다. 하지만, 얕은 레이어 구성은 Overfitting 되기 쉽고, 따라서 레이어를 깊이 쌓는 것이 일반적인 딥러닝 트렌드가 되었습니다. 그래서 이미지 분류에서 과거 뛰어난 성능을 보였던 모델들은 모두 점차 깊어지면서 성능 향상을 이뤘습니다. AlexNet에서 시작해서 VGG network 그리고 GoogleNet (Inception v1) 이 그 예가 됩니다. 하지만 Neural Network가 깊어질수록 Vanishing gradient 문제에 취약해지고 성능에 악영향을 주었습니다. Vanishing gradient를 해결하기 위해서 ResNet에서 제시한 방법은 각 레이어를 통과할 때, identity mapping을 하는 통로를 열어주는 것입니다. 이를 가리켜 Residual connection이라고 부르고, 비유적으로 지름길 (shortcut)이라고 볼 수 있습니다.

identity mapping 통로를 붙여주면 Vanishing gradient 문제에서 자유로워집니다. 먼저, F(x) + x 에서 발생한 gradient는 F(x)를 통과하며 해당 weight layer의 gradient와 곱해지면서, 마찬가지로 gradient가 작아지지만, identity x 쪽은 gradient가 작아지는 일 없이 그대로 Backpropagation 할 수 있습니다. add 연산이 gradient distributor임을 기억하면, 이 레이어의 인풋이 되는 x의 gradient는 $\nabla F(x) + \nabla (identity \ x)$로 계산할 수 있으니, 만일 전자가 Vanishing된다고 하더라도, 후자가 gradient를 그대로 보존하고 있으니 gradient가 완전히 사라지는 일은 없습니다. 또한 Residual connection이 있다면, identity x 쪽에서 중요한 feature를 보존하고 (예를 들어, 개-고양이 분류라면, 고양이의 귀 정보), weight layer가 나머지 부분 (Residual)을 집중해서 학습하여 성능이 향상된다고 해석할 수 있습니다. 상대적으로 이미 찾아낸 주요한 feature의 손상을 최소화하고, 중복될 수 있는 weight layer의 임무를 덜어줄 수 있는 것입니다.
(i) How to determine the architecture of ResNet?
실제 ResNet 구조에서는 identity mappings이 아닌 부분에 대한 실험은 별도로 진행하지 않았습니다. 더불어 논문에서는 깊은 레이어에 대해서 뛰어난 성능을 보였지만, 이상하게도 1202-layer짜리 아주 깊은 (그 당시 기준) 네트워크는 학습하는 데 실패했습니다. 동일한 저자는 이를 태클링하고 identity mappings이 아닌 부분에 대한 다양한 변종에 대한 실험을 덧붙여서 최적의 구조를 제시했습니다 [2].

(ii) Improved ResNet (DenseNet, ResNeXt)
(1) DenseNet [3]에서는 ResNet에서 제안한 Connection의 효율을 극대화하기 위해서 모든 레이어를 서로 잇는 방법을 제안합니다. 또한 각 layer별로 채널이 달라지기 때문에 , add하는 대신 feature map은 채널로 concatenation 돼서 연산됩니다. 이런 구조에서는 각 레이어에서 나온 모든 feature map의 정보를 보존하여 사용할 수 있습니다. 한편, 채널이 지나치게 증가하여 연산이 비싸지는 것을 방지하고자, Dense Block 이후에 Transition Layer를 두어 채널을 허용될 정도로 줄이는 구조를 취하고 있습니다.


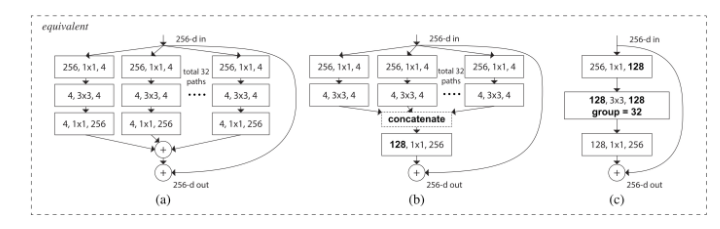
(2) ResNeXt [4] 는 ResNet의 아이디어와 Inception 모듈의 아이디어를 합쳐서 흡사 앙상블 전략을 취했습니다.
Conclusion
이 포스팅에서는 ResNet의 코어 아이디어를 복습하고, 해당 논문을 발전시킨 연구방향에 대해서 알아봤습니다.
[1]. K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385,2015.
[2] K. He, X. Zhang, S. Ren, and J. Sun. Identity Mappings in Deep Residual Networks. arXiv preprint arXiv:1603.05027v3,2016.
[3]. G. Huang, Z. Liu, K. Q. Weinberger and L. Maaten. Densely Connected Convolutional Networks. arXiv:1608.06993v3,2016.
[4] S. Xie, R. Girshick, P. Dollar, Z. Tu and K. He. Aggregated Residual Transformations for Deep Neural Networks. arXiv preprint arXiv:1611.05431v1,2016.
'Machine Learning' 카테고리의 다른 글
| Attention? Attention! (Korean Version) (1) | 2020.07.25 |
|---|---|
| 2 Viewpoints of MSE vs Cross-entropy loss (0) | 2020.04.11 |